Introducing Gateway API Inference Extension
Modern generative AI and large language model (LLM) services create unique traffic-routing challenges on Kubernetes. Unlike typical short-lived, stateless web requests, LLM inference sessions are often long-running, resource-intensive, and partially stateful. For example, a single GPU-backed model server may keep multiple inference sessions active and maintain in-memory token caches.
Traditional load balancers focused on HTTP path or round-robin lack the specialized capabilities needed for these workloads. They also don’t account for model identity or request criticality (e.g., interactive chat vs. batch jobs). Organizations often patch together ad-hoc solutions, but a standardized approach is missing.
Gateway API Inference Extension
Gateway API Inference Extension was created to address this gap by building on the existing Gateway API, adding inference-specific routing capabilities while retaining the familiar model of Gateways and HTTPRoutes. By adding an inference extension to your existing gateway, you effectively transform it into an Inference Gateway, enabling you to self-host GenAI/LLMs with a “model-as-a-service” mindset.
The project’s goal is to improve and standardize routing to inference workloads across the ecosystem. Key objectives include enabling model-aware routing, supporting per-request criticalities, facilitating safe model roll-outs, and optimizing load balancing based on real-time model metrics. By achieving these, the project aims to reduce latency and improve accelerator (GPU) utilization for AI workloads.
How it works
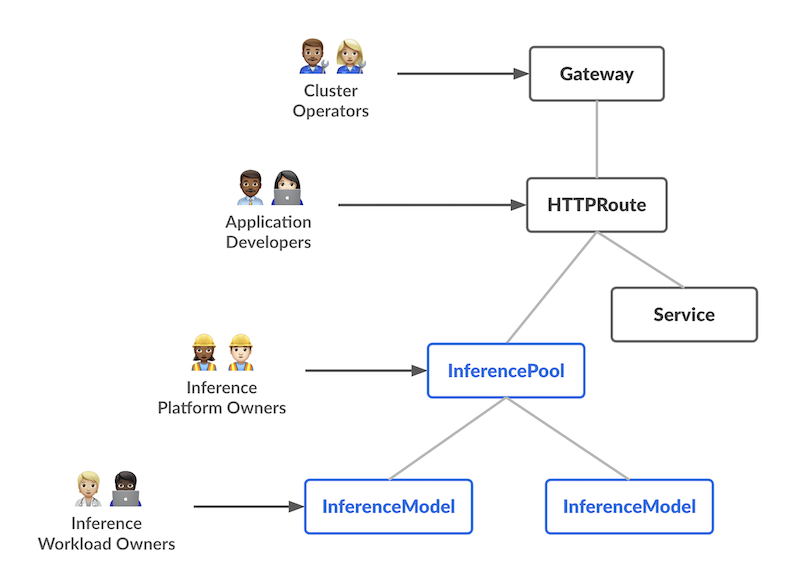
The design introduces two new Custom Resources (CRDs) with distinct responsibilities, each aligning with a specific user persona in the AI/ML serving workflow:
-
InferencePool Defines a pool of pods (model servers) running on shared compute (e.g., GPU nodes). The platform admin can configure how these pods are deployed, scaled, and balanced. An InferencePool ensures consistent resource usage and enforces platform-wide policies. An InferencePool is similar to a Service but specialized for AI/ML serving needs and aware of the model-serving protocol.
-
InferenceModel A user-facing model endpoint managed by AI/ML owners. It maps a public name (e.g., "gpt-4-chat") to the actual model within an InferencePool. This lets workload owners specify which models (and optional fine-tuning) they want served, plus a traffic-splitting or prioritization policy.
In summary, the InferenceModel API lets AI/ML owners manage what is served, while the InferencePool lets platform operators manage where and how it’s served.
Request flow
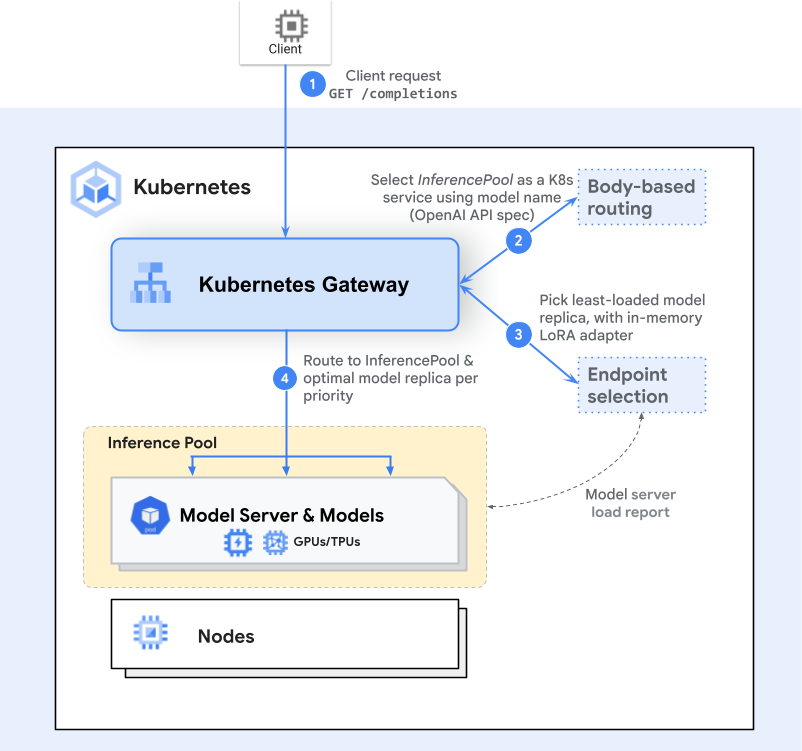
The flow of a request builds on the Gateway API model (Gateways and HTTPRoutes) with one or more extra inference-aware steps (extensions) in the middle. Here’s a high-level example of the request flow with the Endpoint Selection Extension (ESE):
-
Gateway Routing
A client sends a request (e.g., an HTTP POST to /completions). The Gateway (like Envoy) examines the HTTPRoute and identifies the matching InferencePool backend. -
Endpoint Selection
Instead of simply forwarding to any available pod, the Gateway consults an inference-specific routing extension— the Endpoint Selection Extension—to pick the best of the available pods. This extension examines live pod metrics (queue lengths, memory usage, loaded adapters) to choose the ideal pod for the request. -
Inference-Aware Scheduling
The chosen pod is the one that can handle the request with the lowest latency or highest efficiency, given the user’s criticality or resource needs. The Gateway then forwards traffic to that specific pod.
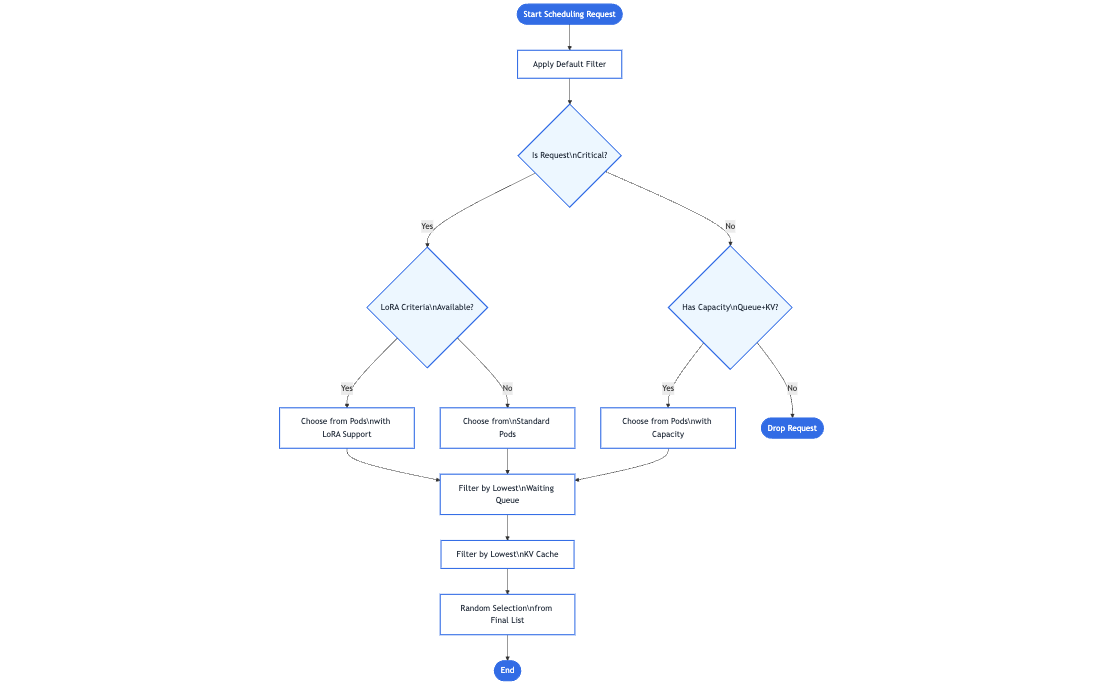
This extra step provides a smarter, model-aware routing mechanism that still feels like a normal single request to the client. Additionally, the design is extensible—any Inference Gateway can be enhanced with additional inference-specific extensions to handle new routing strategies, advanced scheduling logic, or specialized hardware needs. As the project continues to grow, contributors are encouraged to develop new extensions that are fully compatible with the same underlying Gateway API model, further expanding the possibilities for efficient and intelligent GenAI/LLM routing.
Benchmarks
We evaluated this extension against a standard Kubernetes Service for a vLLM‐based model serving deployment. The test environment consisted of multiple H100 (80 GB) GPU pods running vLLM (version 1) on a Kubernetes cluster, with 10 Llama2 model replicas. The Latency Profile Generator (LPG) tool was used to generate traffic and measure throughput, latency, and other metrics. The ShareGPT dataset served as the workload, and traffic was ramped from 100 Queries per Second (QPS) up to 1000 QPS.
Key results
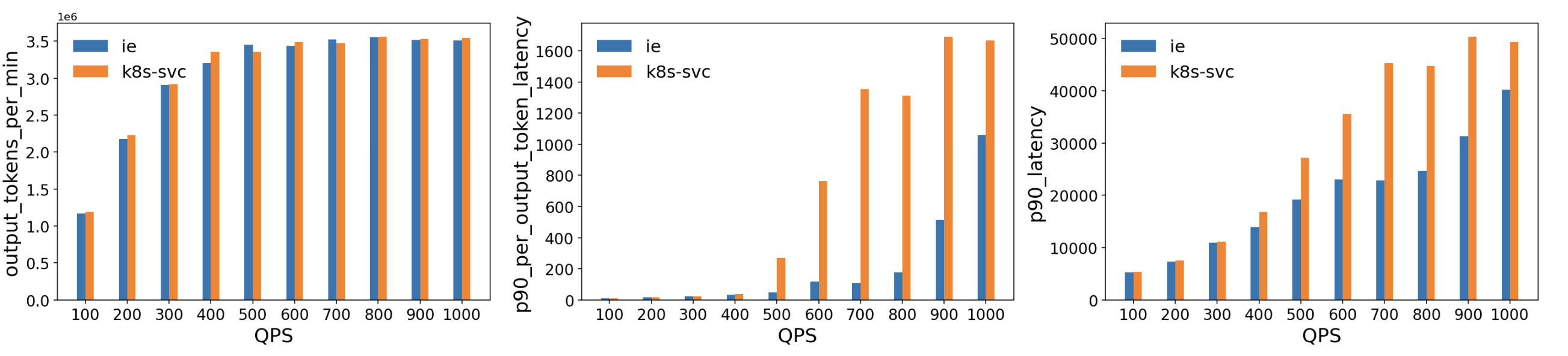
-
Comparable Throughput: Throughout the tested QPS range, the ESE delivered throughput roughly on par with a standard Kubernetes Service.
-
Lower Latency:
- Per‐Output‐Token Latency: The ESE showed significantly lower p90 latency at higher QPS (500+), indicating that its model-aware routing decisions reduce queueing and resource contention as GPU memory approaches saturation.
- Overall p90 Latency: Similar trends emerged, with the ESE reducing end‐to‐end tail latencies compared to the baseline, particularly as traffic increased beyond 400–500 QPS.
These results suggest that this extension's model‐aware routing significantly reduced latency for GPU‐backed LLM workloads. By dynamically selecting the least‐loaded or best‐performing model server, it avoids hotspots that can appear when using traditional load balancing methods for large, long‐running inference requests.
Roadmap
As the Gateway API Inference Extension heads toward GA, planned features include:
- Prefix-cache aware load balancing for remote caches
- LoRA adapter pipelines for automated rollout
- Fairness and priority between workloads in the same criticality band
- HPA support for scaling based on aggregate, per-model metrics
- Support for large multi-modal inputs/outputs
- Additional model types (e.g., diffusion models)
- Heterogeneous accelerators (serving on multiple accelerator types with latency- and cost-aware load balancing)
- Disaggregated serving for independently scaling pools
Summary
By aligning model serving with Kubernetes-native tooling, Gateway API Inference Extension aims to simplify and standardize how AI/ML traffic is routed. With model-aware routing, criticality-based prioritization, and more, it helps ops teams deliver the right LLM services to the right users—smoothly and efficiently.
Ready to learn more? Visit the project docs to dive deeper, give an Inference Gateway extension a try with a few simple steps, and get involved if you’re interested in contributing to the project!